


(Garrykillian/Shutterstock)
Fine fine -tuning is the decisive process in optimizing the performance of pre -trained LLM. It includes further training of the model on a smaller, more specific data set adapted to a specific task or domain. This process allows a large language model (LLM) to adapt your existing and ability to excel in specific applications such as questions, text summary or code generation. Gentle fine -tuning allows the integration of knowledge and terminology specific to the domain that could be added to the original data before training. It can also help match the LLM output and format style with specific requirements.
However, traditional fine -tuning methods are not without restrictions. They usually require a significant amount of high -quality, marked training data that can be expensive and time consuming to obtain or create. Even after fine -tuning, the model may still be prone to generating inaccuracies if the training data is not sufficiently understandable or if the basic model has its own distortion. The fine -tuning process itself can also intensive, especially in very large models.
Most importantly, traditional fine fine -tuning may not effectively instill deep, structured knowledge or robust considering. For example, fine -tuning under supervision includes training on issues to peers to optimize performance. Although it can improve the ability of the model to answer questions, it may not need to be improved its basic underestimation of the subject.
Despite its usefulness in adapting LLM for specific purposes, traditional fine -tuning often does not achieve the provision of a deep billing grounding necessary for the truly reliable and accurate performance in domains that require extensive knowledge. Simply providing multiple questions answers Peirs may not solve the basic lack of structured knowledge and ability to think in these models.

(A-Image/Shutterstock)
Unlocking the improved LLM fine fine -tuning through knowledge grapes
The use of knowledge graphs (KGS) offers a strong approach to strengthening the fine tuning process for LLM and effectively deals with many restrictions associated with traditional methods. Integration of structured and semantic KGS knowledge can create LLMS, more reliable and reliable and context. Several techniques make this integration easier.
One meaningful way to improve LLM fine -tuning is an increase in training data. KGS can be used to generate high -quality data files that exceed simple answers. A remarkable test is the KG-SUP frame (knowledge graph-under supervision). This framework uses the knowledge charts to generate detailed explanations for each few questions in a pair of answers in the training data. The main idea of KG-SFT is that by providing LLMS these structured explanations during the fine-tuning process can develop a deeper understanding of the basic and logic associated with questions and answers.
KG-SFT usually consists of three main components:
- An extractor that identifies entities in a pair of Q&A and reads related to the thinking of subgraphs from kg;
- A generator that uses these subgraphs to create smooth explanations; and
- A detector that ensures the reliability of generated explanations identification of potential knowledge conflict.
This approach offers several advantages, including improved ACCCAAIR, especially in scenarios where the marked training data are rare, and increased LLM knowledge. By providing structured explanations from the graphs of knowledge, fine fine -tuning can shift as a mere recognition of patterns and focus on the installation of a real understanding of knowledge and justification for it. Traditional fine -tuning could teach LLM the right answer to the question, but the methods of KG controlled can help him understand that it is the correct use of structured relationships and semantic information with the knowledge chart.
Incorporate the insertion of the knowledge chart
Another powerful technique includes the integration of the graph of the knowledge graph into the LLM fine fine -tuning process. The insertion of the knowledge chart is the vector representation of entities and relationships within KG, which capture their semantic meanings in a dense format of numbers. These insertion can be used to injure structured knowledge from the graph directly into LLM during fine fine -tuning.
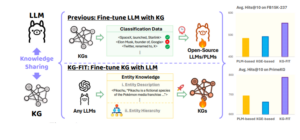
“Fine tune llm with kg” vs “fine fine-tuning kg with llm (source: kg-fit: Nowledge Graph fine fine-tuning on open-world nowge)
KG-Fit is an exploration of this technical technical technical technology. It uses improvement led by LLM to create the hierarchical structure of clusters of entity from the nowlege graph. This hierarchical is now, together with text information, during the fine fine -tuning of LLM. This method has the potential to capture both a wide contextual semantics, that LLM is good in understanding and more specific relational semantics, which is its own knowledge charts.
By inserting knowledge from the chart, LLMS can access the user information in a more efficient and finer way compared to a simple text description of this now. These insertion can capture an intrial semantic connection between entities in kg in a format that LLMS can easily process and integrate into their internal representations.
Tuning the language model of the aligned chart (glam)
Frameworks as Graph-Ruld Language Model) occupy another innovative approach to using knowledge graphs for fine fine-tuning LLM. Glam works by transforming a graph of knowledge into an alternative text representation, which included marked peers of the answer to the question derived from the structure and content of the graph. This transformed data are then used to fine -tune the LLM and effectively by grouping the model directly into the knowledge contained in the graph. This direct alignment with knowledge based on the graph increases the capacity of LLM to think about the structured relationships present in the kg.
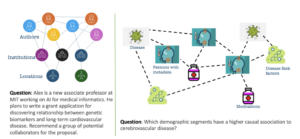
Figure 1: Motivation of example for alignment of basic models with knowledge -specific knowledge charts. The left picture demomises the question where LLM needs to be integrated with a graph of knowledge derived from the social network. The right figure Demonstrates the need where LLM needs to integrate with the patient’s profiles into the disease extracted from the electronics Database of healthcare records (Source: GLAM: tuning of large languages for aligning the graph of domain knowledge through the division of neighborhood and generative subgraf coding)
For certain tasks that arelated on structured knowledge, this approach can serve as an alternative to methods based on generation (rag). By direct alignment of LLM with the structure of the knowledge chart during the fine phase, it is possible to achieve deeper integration of knowledge and improved thinking capabilities. The purpose of this method is Intoread mere obtaining information from KG at the time of conclusion is the intention of structural information the graph in the LLM parameters, which allows it to more effectively consider relationships between entities.
Tuning Instructions for NOWLEDGE GRAPH INTERACTION
LLMS can also be fine -tuned to improve their ability to interact with knowledge charts. This includes LLM training on specific instructions that lead it in tasks, such as generating questions in chart questions such as Sparql or extracting specific information from KG. In addition, LLMS can be invited to extract entities and relationships from the text, which can then be used to design the knowledge graphs. LLM tuning in such tasks can further improve its understanding of graph structures and improve extraction accuracy.
After undergoing such fine fine -tuning, LLM can be used to automate the creation of Nowlege graphs from unstructured data AC and more sophisticated questions against Égsting KGS. This process recalls LLMS with specific skills needed for efficient navigation and the use of structured information continuing in knowledge charts, leading to a more fluent integration between them.
Attack on excellent performance and reliability of LLM
Improved LLM fine -tuning capabilities now provide graphs with a convincing new reason for organizations to invest in this technology, especially at the age of Genai. This approach offers important benfits that directly solve the reduction of traditional LLM and traditional fine -tuning methods. LLM fine fine -tuning with knowledge stiffened from verified knowledge charts significantly reduces the incidence of hallucinations and increases the accuracy of their output billing. Knowledge graphs serve as a reliable source of truth and provide LLMS the basis of verified facts to store their reactions.
For example, the graph can now provide real, verified facts, which AI allows you to get accurate information before generating the text, preventing the production from producing. In critical applications where accuracy is paramount, such as health, financial and legal areas, this ability is essential. Organizations can deploy solutions to LLM-distributed in these sensitive areas with greater confidence and confidence by significantly decreased incorrect information.
About the author: Andreas Blumauer is a senior growth of VP, Graphi AI’s leading provider, and a new created company as a result of the focus of Ontotext with a semantic web company. You want to learn more, visit https://graphWise.ai/ or watch on LinkedIn.
Related items:
Future Genai: How Graphrag improves Accairy and Powers llm accairy
What is a vector, Victor?
Why young developers get the knowledge charts
(Tagstotranslate) Gentle fine-tuning